RTX 3060 vs Jetson AGX for BERT-Large
This article compares the performance and energy efficiency of the RTX 3060 vs the Jetson AGX when running BERT-Large training and inference tasks. This article also looks at the effects of batch size and Automatic Mixed Precision, i.e. FP16 mode, on performance. The benchmark task is the Hugging Face CoNLL-2003 token-classification example, with the PyTorch backend.
The NVIDIA RTX 3060 is a graphics card released in February 2021, and includes 12GB of VRAM. The RTX 3060 includes 28 Streaming Multi-Processors, 112 Tensor Cores, and has 12 TFLOPS of General Purpose (GP) FP16 processing power. High VRAM is a necessity for ML researchers, and makes this card an alternative to expensive Quadro or Titan cards. Unfortunately, at the time of writing, this graphics card is impossible to purchase at the retail price of $420 CAD (current market price: $900 CAD).
The NVIDIA Jetson AGX Xavier module is a Single Board Computer (SBC) released in the second half of 2018, which includes 32GB of RAM shared with the on-board Volta GPU and the CPU. The Jetson AGX includes 8 Streaming Multi-Processors, 64 Tensor Cores (equivalent to 32 GeForce 30-series Tensor Cores), and has 2.8 TFLOPS of GP FP16 processing power. This SBC was designed with low-power inference tasks in mind, but can be used for training BERT-Large as well. The Jetson AGX Developer Kit retails for around $890 CAD.
On paper, the RTX 3060 appears to have 8x the FP32, 4x the GP FP16, and 3.5x the Tensor Core performance compared to the Jetson AGX. However, we will see that the performance changes drastically with different PyTorch modes, and that the RTX 3060 is surprisingly efficient for inference-only tasks.
Test Bench Setup
RTX 3060
Motherboard: AsRock Rack C236M WS
RAM: 16GB DDR4 ECC 2400MHz
CPU: 4-Core E3-1245v6, 3.7GHz (No Hyperthreading)
GPU: EVGA GeForce RTX 3060 XC
VRAM: 12GB GDDR6, 360GB/s
OS: Ubuntu 20.04
PyTorch: 1.8.0 (CUDA Build)
CUDA: 11.1.1
Jetson AGX
SBC: Jetson AGX Xavier
RAM: Shared VRAM
CPU: 8-Core ARM v8 CPU, 2.2GHz
GPU: 512-Core Volta GPU
VRAM: 32GB LPDDR4x, 137GB/s
OS: Ubuntu 18.04
PyTorch: 1.8.0 (Jetson Build)
CUDA: 10.2 (JetPack 4.5.1)
Benchmark
The CoNLL-2003 classification example from the Hugging Face Transformers Library was used as a benchmark. This task involves classifying each word in a sentence as either "Person", "Place", "Organization", or "None". The specific version of the library used was v4.3.3. Gradient accumulation will be used to achieve reasonable batch sizes when performing training. This will be indicated by a total batch size of m x n, where m is the number of accumulation steps and n is the device batch size. A sequence length of 512 tokens was used at all times. Lastly, on the RTX 3060, the benchmark was tested with both TF32 support enabled and disabled.
Memory Usage
Training
The RTX 3060 finally has enough VRAM (12053 MiB) to train BERT-Large in both FP16 and FP32 mode, albeit with a batch size of 2. Gradient accumulation will then allow an arbitrary total batch size. nvidia-smi reports that the 12x2 batch size uses 10473 MiB and 10495 MiB for FP16 and FP32 modes respectively. A batch size of 3 will OOM in FP32 mode, and will OOM in FP16 mode if starting from a checkpoint. Don't do it!
The Jetson AGX easily supports batch sizes of 8 or more in both FP16 and FP32 mode, with a total RAM size of 32GB. The system RAM usage was measured with free -mh. A batch size of 3x8 uses approximately 21GB and 24GB RAM for FP16 and FP32 modes respectively.
When doing CPU only training in FP32 mode, the system RAM usage for a batch size of 24x1 was 9GB, 12x2 was 12 GB, and 8x3 was 15GB.
Inference
Inference has much lower RAM requirements, since the gradient does not need to be calculated.
Batch RTX 3060 Jetson AGX
Size (VRAM) (RAM)
8 3 GB 4 GB
16 3 GB 6 GB
32 4 GB 6 GB
64 6 GB 7 GB
Performance Analysis
Maximum performance is important for those who want to experiment with multiple models, or train with faster turnaround times. This is also useful for those who need to run inference tasks on a deadline. I used the default PL of 170W on the RTX 3060, and Mode 0 (MaxN) on the Jetson AGX.
Training
The RTX 3060 is 3x faster than the Jetson AGX at FP16 training, and 4x faster at general-purpose FP32 (TF32=False) training.
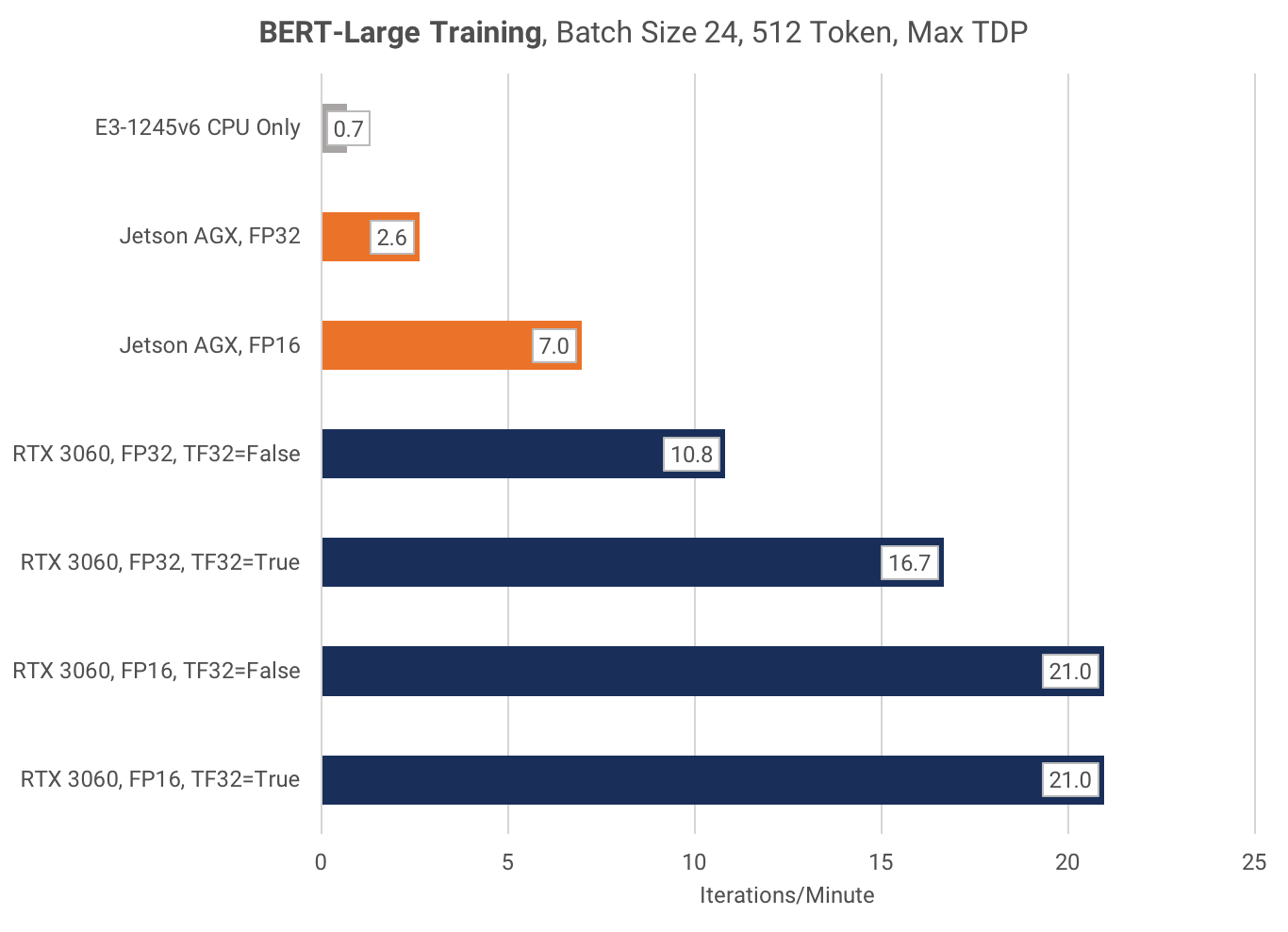
Inference
Inference testing was done with FP16 only. The RTX 3060 was approximately 7x faster than the Jetson AGX at FP16 inference.
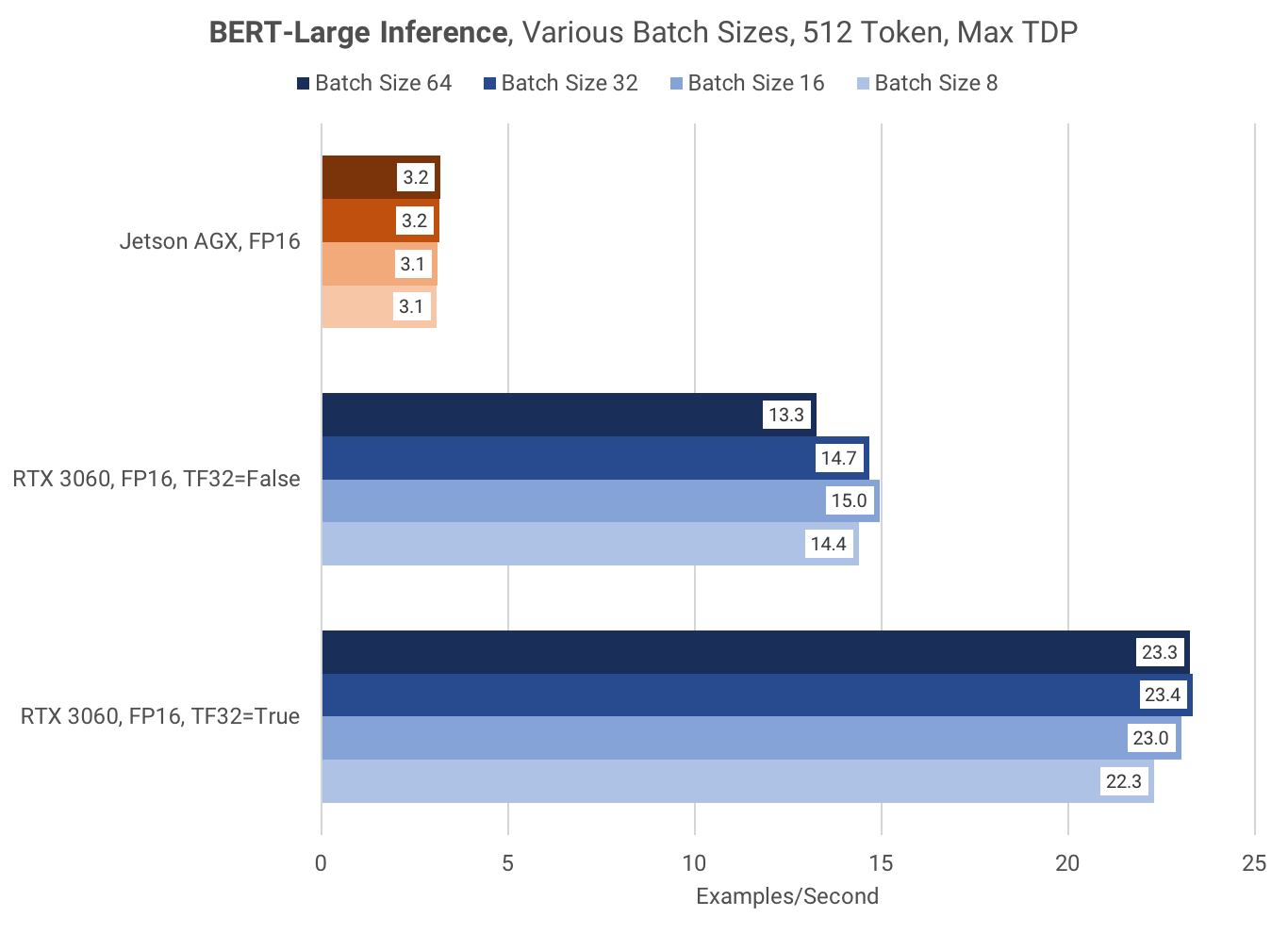
Efficiency Analysis
Power efficiency is crucial for low-power applications or models that run for long periods of time.
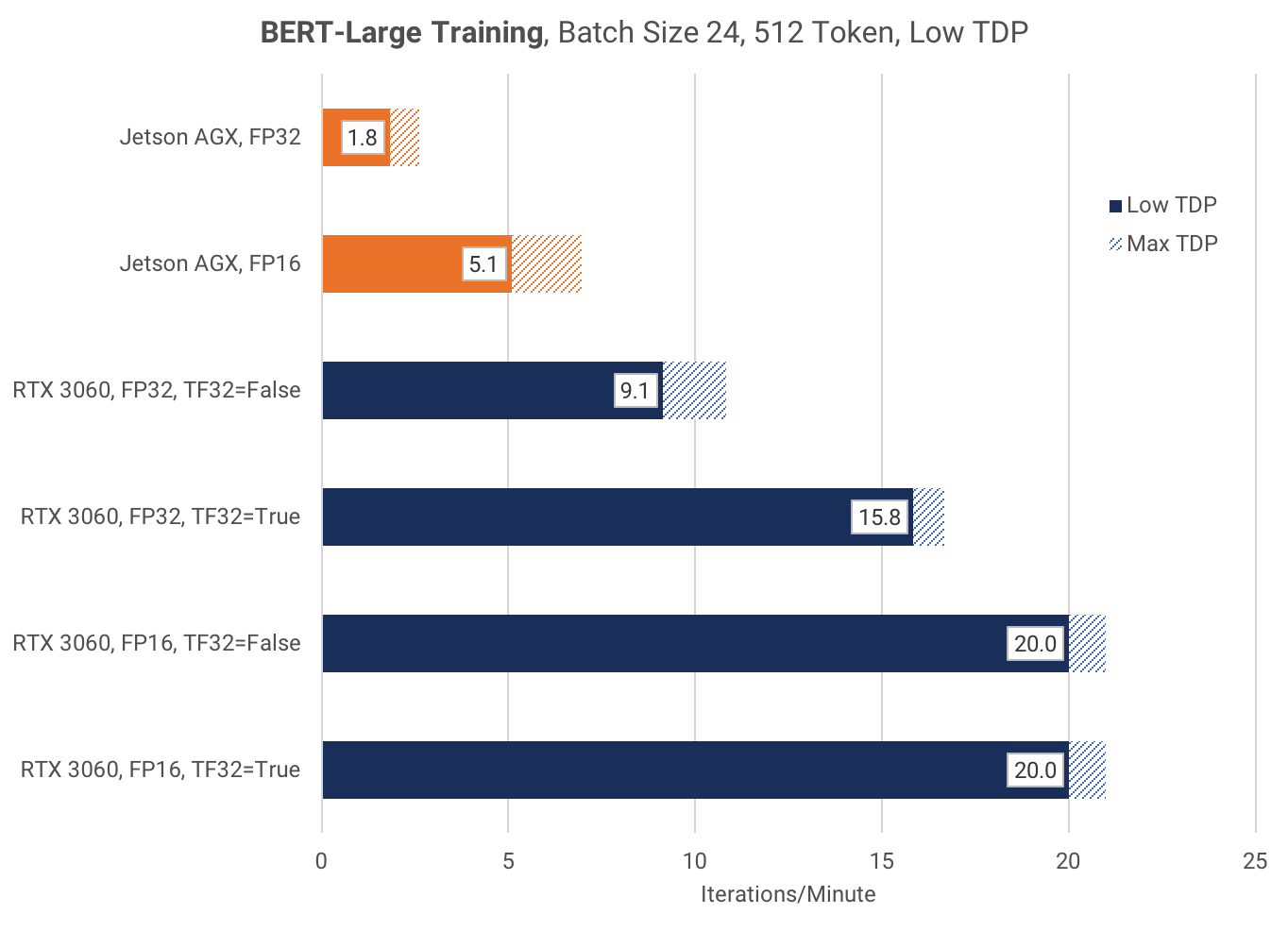
The RTX 3060 Power Limit (PL) can be modified with the nvidia-smi command, and the Jetson AGX Power Mode can be modified with the nvpmodel command. For these benchmarks, I tested the RTX 3060 at the default PL of 170W, and the lowest PL of 100W. For the Jetson AGX, I tested both Mode 0 (no-limits) and Mode 6 (<30W).
Training
By changing from Mode 0 to Mode 6, the Jetson AGX FP16 training speed falls by 27%. However, the RTX 3060 FP16 training speed only falls by 5% after lowering from PL 170W to PL 100W.
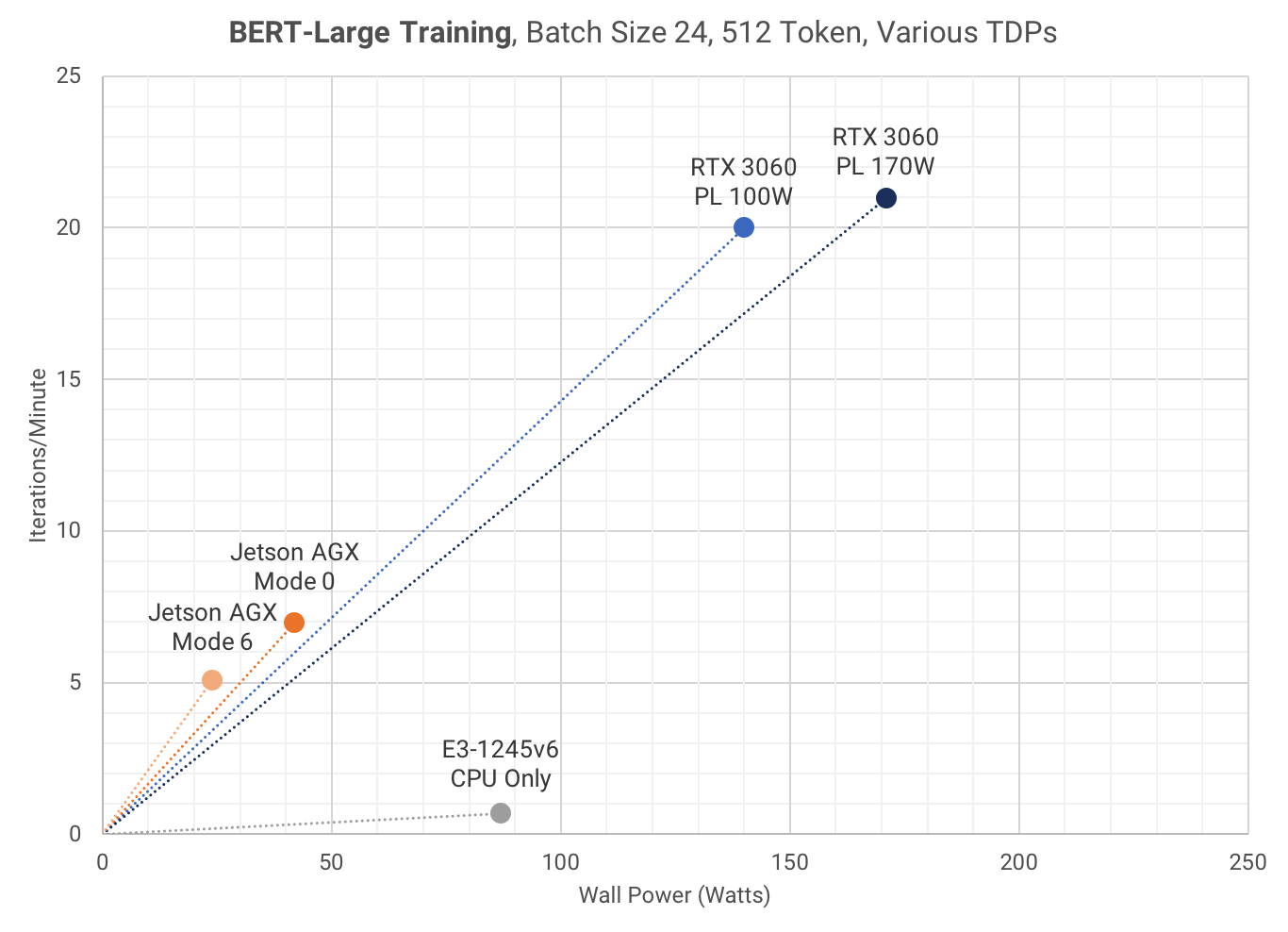
The following scatter plot shows Wall Power vs Training Speed. Each data point represents the highest training speed for a device's given power limit. The Jetson AGX Mode 6 is the most power efficient, at 283 Joule/Iteration. The RTX 3060 PL 100W uses 50% more power, at 420 Joule/Iteration (🚀🚀🚀).
Inference
By changing from Mode 0 to Mode 6, the Jetson AGX FP16 inference speed falls by 31%. However, the RTX 3060 FP16 inference speed only falls by 12% after lowering from PL 170W to PL 100W. There also seems to be a bug with TF32=False in inference mode.
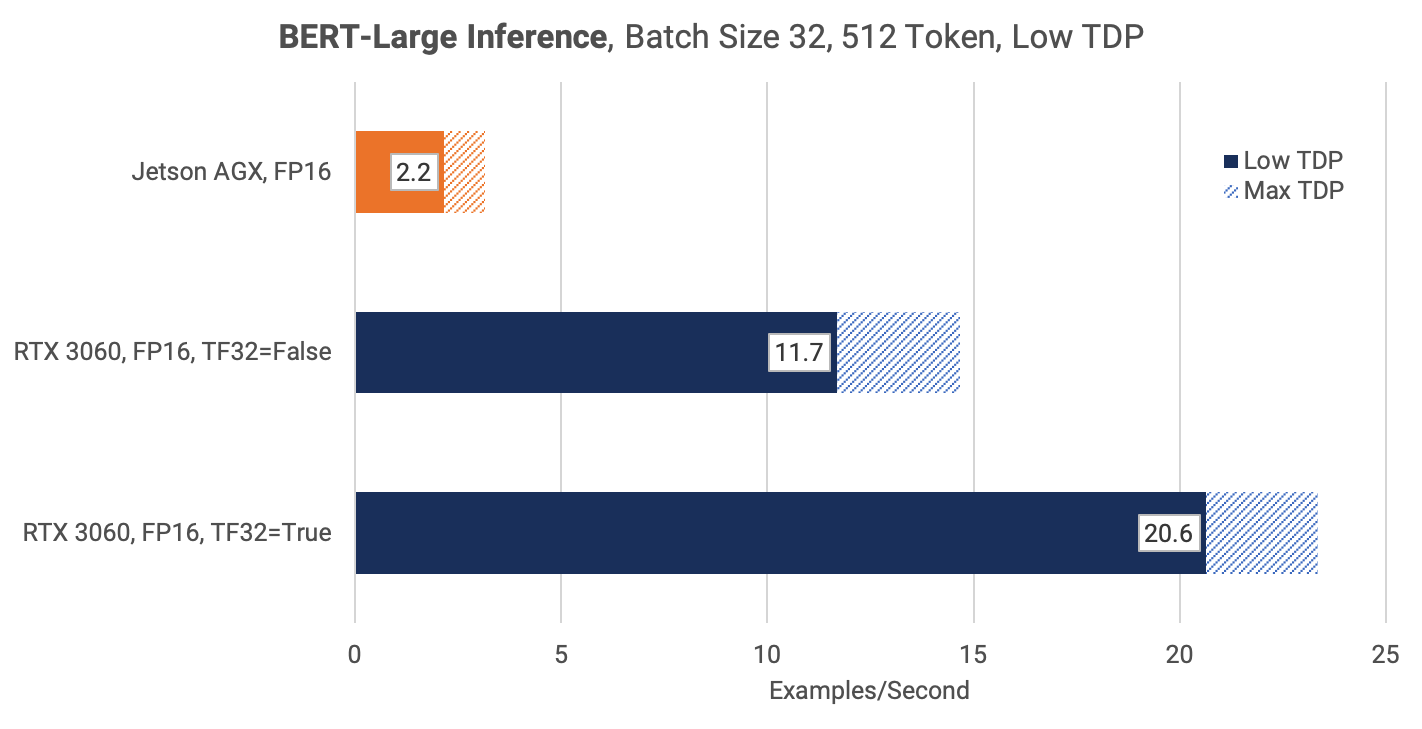
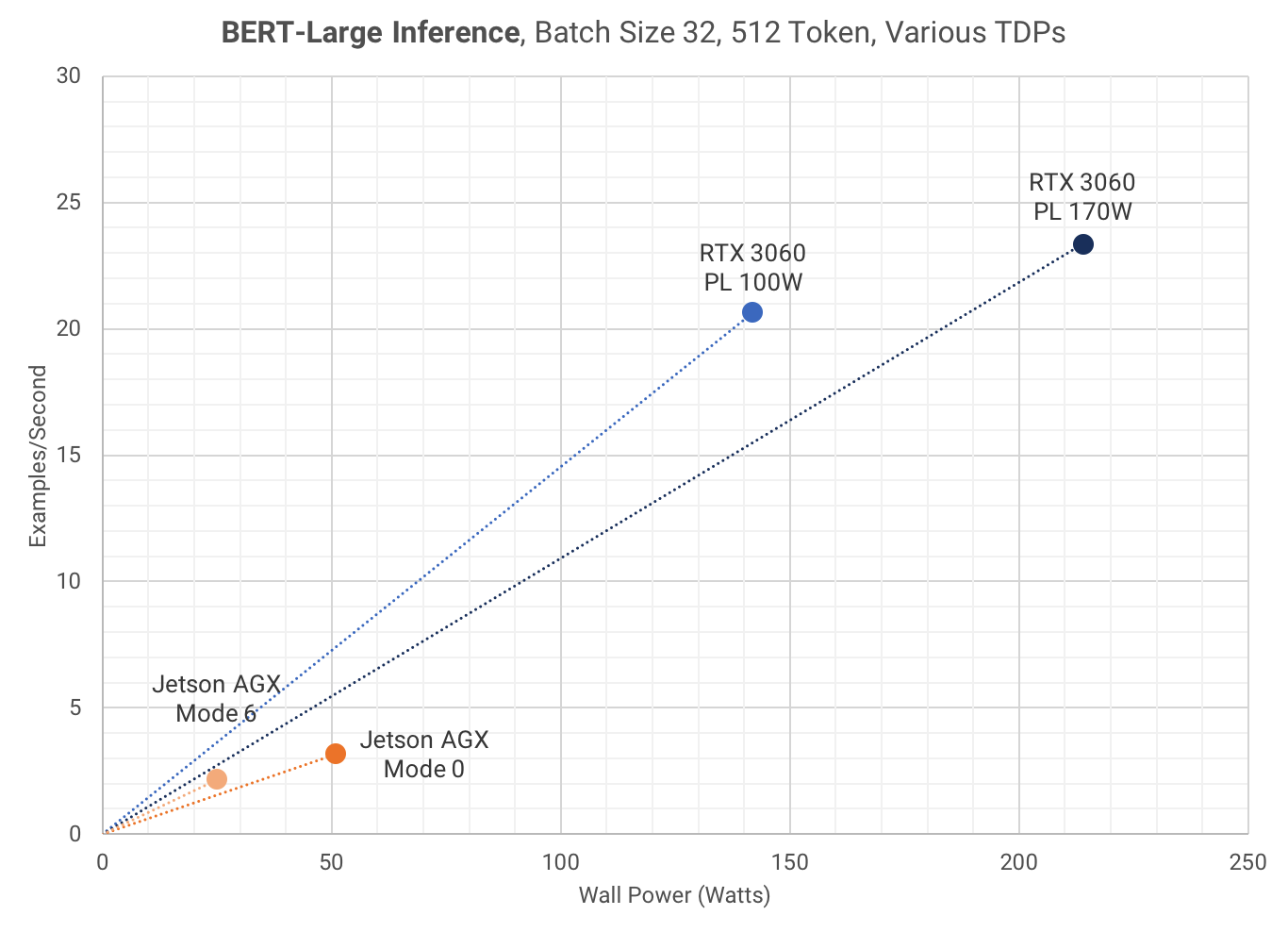
The following scatter plot shows Wall Power vs Inference Speed. Each data point represents the highest inference speed for a device's given power limit. This graph is extremely surprising, since it shows that the RTX 3060 PL 100W is the most efficient at 6.9 Joule/Example, compared to 11.5 Joule/Example on the Jetson AGX Mode 6.
Idle Power Usage
The RTX 3060 Test Bench uses 26W at idle, and ~1W when shutdown. The Jetson AGX SBC uses 6W at idle (all modes), and ~0W when shutdown.
Conclusion (or not)
I'm way too tired to write a proper conclusion, and I've spent too many hours changing fonts in Excel. TLDR: the RTX 3060 is great. Get it! Also, isn't it strange that the Jetson AGX, a device designed for low-power inference is more efficient at training than the RTX 3060, but less efficient at inference?
Bonus Benchmark!
Does Dual-Channel vs Single-Channel RAM affect the training performance of the RTX 3060? This benchmark uses the token-classification example with BERT-Base (FP16, TF32=True, PL 100W).
Single Dual
Batch Channel Channel
Size it/sec it/sec %diff
2 8.59 8.57 0
4 5.47 5.46 0
8 3.18 3.17 0
12 2.24 2.23 0
16 OOM OOM
2x8 1.68 1.66 1
The answer is no!