Failover Networking with Hoppy + IPv6
Introduction
In this guide I describe a minimal failover and fallback setup for a high availability server, using only Debian packages and the Linux kernel. This method requires Debian 12 or newer. Hoppy Network is used to provide a stable public IP address, however methods such as dynamic DNS can be used. Lastly, I'll describe a command to reset WireGuard's sticky routes.
Definitions
Failover networking means that the device will switch to a backup internet connection if the primary connection fails. Fallback means that the device will use the primary connection again if available.
2024: The Year of IPv6
We are currently on track to hit 50% worldwide adoption of IPv6 this year, marking an important milestone in the evolution of network technologies. Internet registries have run out of new IPv4 addresses for quite some time now, and as a temporary solution, CGNAT was introduced to allow multiple end-users to share an IPv4 address. Unfortunately, CGNAT prevents self-hosting servers, because incoming requests from the internet to a local NAT address are blocked. Hoppy Network was launched as a solution to this problem by tunneling incoming packets over a WireGuard connection. IPv6 also attempts to solve this problem by allocating a globally routable address to each device, thus allowing end to end connections without NAT or port forwarding. For those concerned of public exposure to the internet, note that almost all consumer routers have a default-deny firewall.
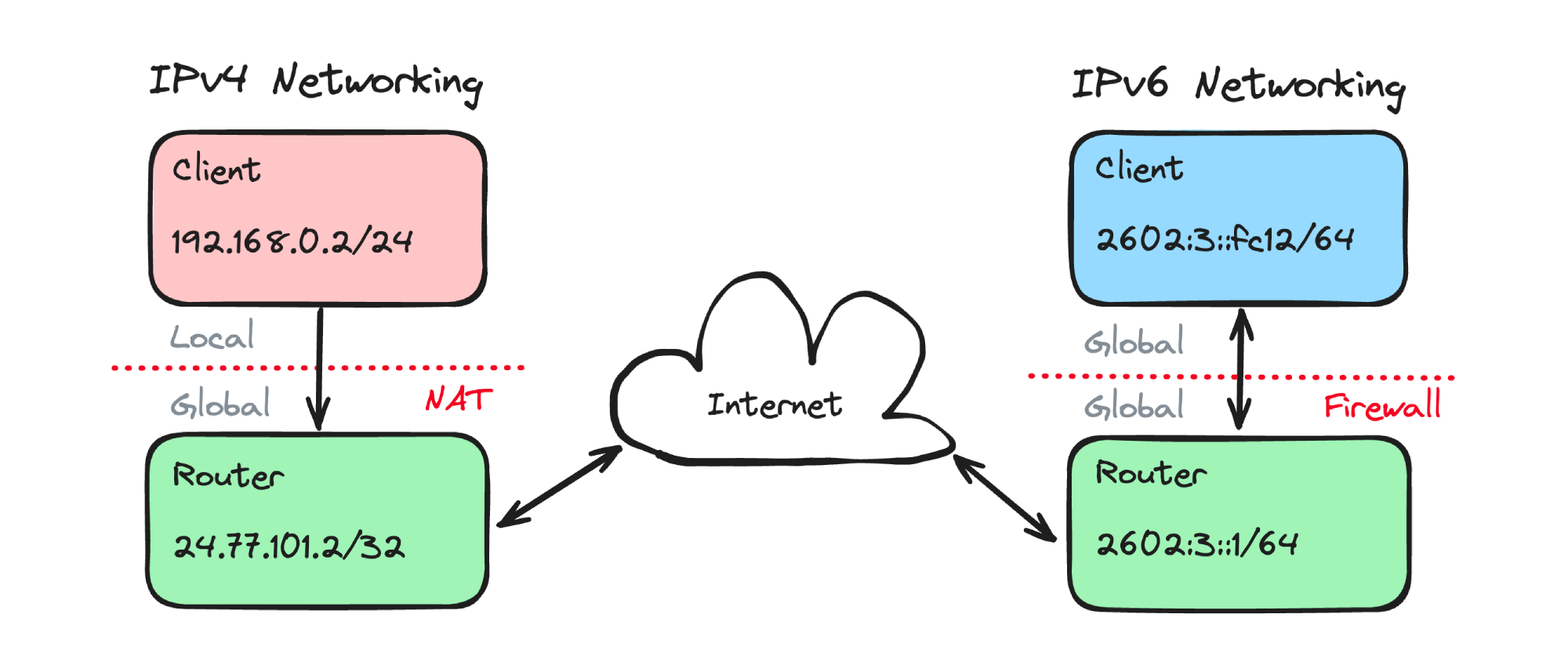
Other notable features include auto-generation of link-local addresses as well as support for multicast ping (e.g. ff02::1%eth0). Confusing or controversial aspects of IPv6 include the square bracket representation and the lack of zone index support in browsers. A novel feature of IPv6 is the ability to be automatically assigned multiple addresses and routes to a single network interface. This can be used for failover, which leads me to:
Strategy 1: Single Interface Multiple Routes
Multiple IPv6 routes can be learned on the same physical network. These routes can also expire quickly if they have a short lifetime. This solution is described on packetlife.net (2011), where two or more IPv6 routers on the network advertise routes with very short lifetimes, on the order of seconds. If the lifetime is too long, this method will not work. Pros: adjustable failover times, no server configuration. Cons: router configuration needed, increases power consumption (battery-powered devices will be unhappy).
Strategy 2: mwan3 and NAT66
For those running OpenWRT, the mwan3 package provide an automatic failover solution. After each connection is on a seperate network interface, the daemon will manage the health status and priority of each interface. There is a detailed setup guide by James White for mwan3 and IPv6. However, it looked quite complicated and I did not test it out. Pros: load-balancing support, real use-case for NAT66! Cons: complex to configure, multiple dependencies
Strategy 3: ra_defrtr_metric ⭐️
This method uses the ra_defrtr_metric sysctl attribute introduced in Linux kernel v6.0, which allows changing the metric (default 1024) for learned IPv6 routes on a per interface basis. The route metric is used by Linux to prioritize certain routes over another, lower numeric values having higher priority. If a route stops responding, Linux will switch to the lower priority one. The primary and failover connections should be on seperate interfaces. This is an excerpt of my /etc/network/interfaces file:
# The primary network interface (IPv4 + IPv6)
auto eth0
iface eth0 inet dhcp
# Route metric defaults to 1024
# The failover network interface (IPv6 only)
allow-hotplug eth1
iface eth1 inet6 auto
# Change route metric to 2048
pre-up sysctl -w net.ipv6.conf.eth1.ra_defrtr_metric=2048
To pick up the advertised IPv6 DNS servers and auto-update /etc/resolv.conf (maximum of 3 DNS servers), run the following:
sudo apt install openresolv rdnssd
This is the output of ip -6 route:
...
default via fe80::XXXX dev eth0 proto ra metric 1024 expires 96sec hoplimit 64 pref medium
default via fe80::XXXX dev eth1 proto ra metric 2048 expires 885sec hoplimit 64 pref medium
Pros: native kernel support, easy configuration. Cons: non-adjustable failover times of ~30 sec
WireGuard Fallback Bug + Fix
When testing this with Hoppy Network, WireGuard would failover to the backup connection as expected, but would not fallback to the primary connection when restored. I ended up doing a deep dive into WireGuard kernel code, but long story short, add the following to your WireGuard conf file:
[Interface]
...
# replace with the appropriate public key and endpoint address/port
PostUp = nohup sh -c 'while true; do wg set %i peer mXXXX= endpoint [2602:XXXX::]:51820 >/dev/null 2>&1; sleep 1; done' & echo $! > /tmp/%i_watchdog.pid
PreDown = sh -c 'kill "$(cat /tmp/%i_watchdog.pid)"' &
If you have multiple peers, you will need multiple wg set commands in the the PostUp block.
Demo
For a live failover demo, check out my YouTube video.
Another Strategy: BGP Multihoming
A different method for providing access to the core of networking is to use Border Gateway Protocol (BGP), which also has failover mechanics. First, get assigned an organizational ID, ASN, and IPv6 block from an internet registrar (e.g. ARIN). Then find two ISPs to multihome the connection (i.e. datacenters). Lastly, obtain proof of ownership and announce the route to BGP peers. Pros: automatic failover, stable IP address, networking street cred 😎. Cons: overkill in low-resource settings.